Leichtgewichtige Prozesse mit Camunda und Zeebe
Durch den Übergang von Camunda 7 zu 8 wandelt sich die Prozessengine von einer Library, welche in Anwendungen integrierbar ist, zu einer umfangreichen Plattform mit vielen Komponenten. Beim Erkunden des empfohlenen Setups begegnen wir Helm Charts und Deployments mit acht und mehr Komponenten, wobei einige im Produktivbetrieb nur für Enterprise-Kunden verfügbar sind. Dieser Artikel zeigt, wie der Open-Source-Kernkomponente Zeebe Prozessapplikationen mit kleinem Fußabdruck erstellt werden können.
Inhaltsverzeichnis
Eine neue Architektur
Es ist selten, dass eine neue Major-Version einer Software einen derart starken Paradigmenwechsel mit sich bringt: War die Camunda Platform in Version 7 noch komplett in Java Applikationen integrierbar, basiert Camunda 8 nun auf Zeebe, einer selbstständigen Komponente, mit welcher unser Code per gRPC kommuniziert. Anstatt den Zustand der Geschäftsprozesse in einer Datenbank abzubilden, werden die Operationen der Prozesse in einem Event Log gespeichert. Das Ziel der Camunda Entwickler war eine Prozessengine zu schaffen, welche Horizontal unbegrenzt skalierbar ist. Damit kann Camunda 8 einen weitaus höheren Durchsatz verarbeiten als Camunda 7, welches nur so viele Requests verarbeiten konnte wie seine zentrale, relationale Datenbank.
Die Komplexität der Camunda Plattform 8
Ein oft diskutierter Punkt an der neuen Plattform ist, dass die Komplexität einer durchschnittlichen Camunda Installation höher ist, als es für die alte Engine der Fall war. Ein produktives Deployment für Camunda 7 umfasste die Engine an sich, eine relationale Datenbank, optional die Taskliste um User Tasks abzuarbeiten und ein Cockpit, um in laufende Prozesse hineinzuschauen. Bis auf die Datenbank konnten wir all diese Komponenten in einer einzelnen Java Applikation bündlen, welche wir mit gewohnten Mitteln deployen konnten.
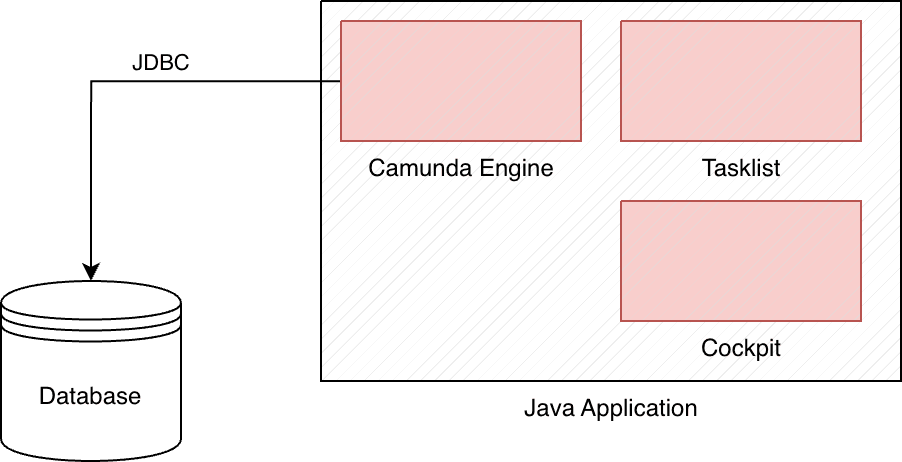
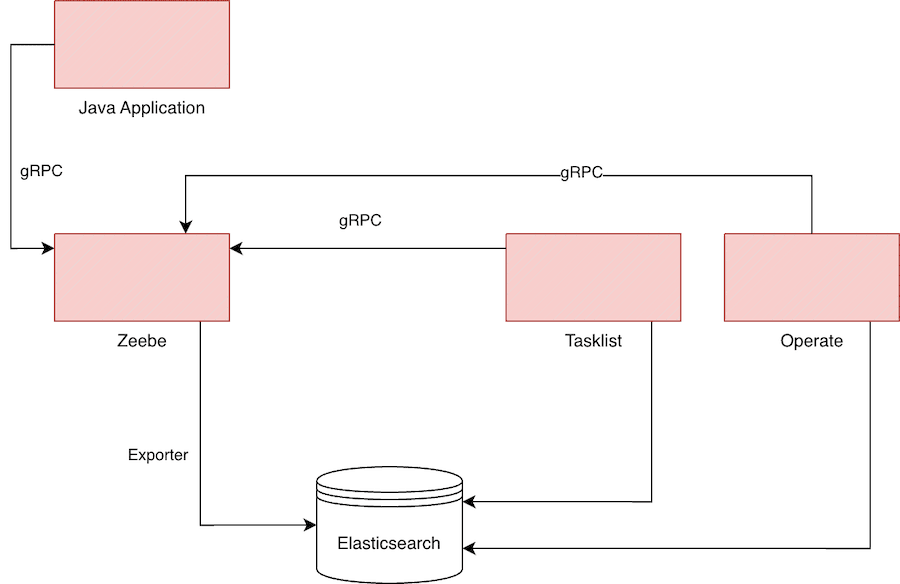
Da die "neue" Zeebe Engine den Zustand der Prozessinstanzen nicht in einer Datenbank ablegt, sondern nur dafür verantwortlich ist die zugehörigen Ereignisse zu orchestrieren und an Job Worker zu delegieren, welche die eigentliche Verarbeitung mit Code vornehmen, gibt es keine API mit welcher wir den Zustand der Prozessinstanzen abfragen können. Es liegt an uns, den Zustand aus den Event-Logs herzustellen und abfragbar zu machen. Hilfsmittel hierfür sind die sogenannten Exporter, Plug-Ins in der Zeebe Engine, welche die Events an Kafka, Redis, Elasticsearch oder andere Speichertechnologien übermitteln, wo sie aggregiert werden können. Dieses Vorgehen nutzt die Camunda Plattform 8 selbst: Die Daten, welche von der Taskliste und dem "Cockpit" Nachfolger "Operate" benutzt werden, liegen in einem Elasticsearch Speicher, welcher Teil des Standard-Deployments ist. Diese Komponenten möchten natürlich alle gewartet und betreut werden, ganz abgesehen vom Ressourcenverbrauch.
Ein weiterer Wermutstropfen: Die grafischen Oberflächen "Tasklist" und "Operate" stehen nicht mehr unter einer Open Source Lizenz, und dürfen unlizensiert (und damit kostenlos) nicht in Produktion betrieben werden (auch wenn wir generell nicht empfehlen würden, unternehmenskritische Open Source Komponenten ohne Wartungsvertrag produktiv zu betreiben).
Eine Prozessengine für Großkonzerne?
Gerade bei den Nutzer:innen der Camunda 7 Community Edition sorgen diese Änderungen für Verunsicherung. Nicht alle haben fachliche Anforderungen an eine Prozessengine, welche die Verwaltung dermaßen vieler Komponenten und die Betreuung eines Kubernetes Clusters rechtfertigen. Die alternative Nutzung des hauseigenen SaaS Produkts Camunda Cloud könnte auch für kleinere Unternehmen sinnvoll sein, hier skalieren die Kosten aber mit den ausgeführten Prozessinstanzen, ein Anwendungsfall sollte also sorgfältig berechnet werden. Der Break-Even-Point, ab welchem Self-Hosting sich lohnt dürfte erst bei einer beachtlichen Anzahl an Prozessinstanzen pro Stunde überschritten werden.
Aber was ist mit kleineren Projekten, welche von einer Prozessorchestrierung und dem Einsatz von BPMN profitieren können, mit der Nutzung des SaaS-Angebots oder dem Betrieb komplexerer Infrastruktur nicht mehr rentabel wären? Im folgenden Beispiel möchten wir dieser Frage nachgehen, indem wir einen leichtgewichtigen Prozess bauen und betreiben.
Beispiel: Ein Erinnerungs-Bot für soziale Netzwerke
Ein "Reminder-Bot" ist ein schönes Beispiel für einen leichtgewichtigen Prozess. Hierbei handelt es sich um einen Account, welcher in einer Nachricht mit dem Zusatz "in x Tagen" erwähnt wird, und nach Ablauf dieser Zeit per Post als Erinnerung antwortet. Als BPMN Prozess könnte dieser beispielsweise so aussehen:
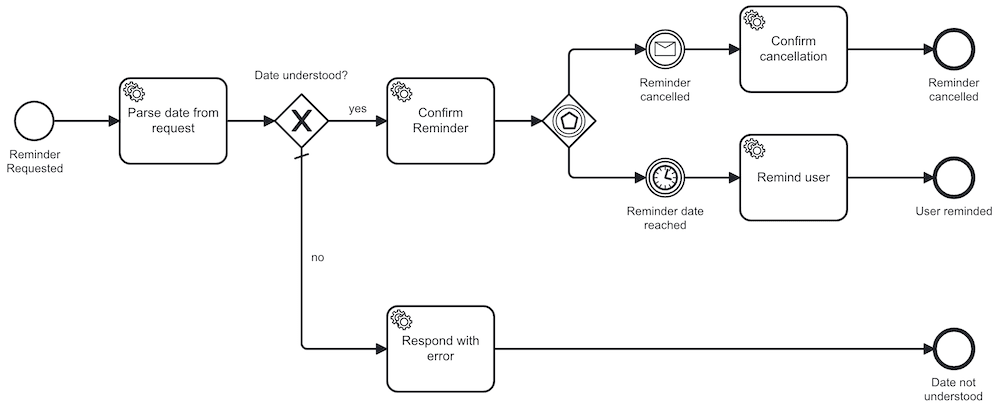
Aus dem Prozessmodell lässt sich der erwünschte Prozessflus transparent ablesen: Wir warten darauf, dass ein:e Nutzer:in eine Erinnerung anfordert, und starten dann den Prozess. Zunächst versuchen wir die Nachricht zu interpretieren. Können wir ein Zeitraum aus dem Text verstehen, oder nicht? Ist dies nicht der Fall, antworten wir mit einer Nachricht auf den Ausgangs-Beitrag und geben zu erkennen, dass wir keine Anweisung verstehen konnten. War uns dies jedoch möglich, bestätigen wir kurz den gesetzten Reminder und warten dann auf das berechnete Datum.
Nun kann einer von zwei Fällen eintreten: Entweder tritt das gewünschte Datum ein und wir schreiben den Reminder, so wie gewünscht. Oder uns wird mit dem Befehl "abbrechen" zu verstehen gegeben, dass der Reminder nicht mehr benötigt wird. In diesem Fall bestätigen wir dies ebenso und beenden den Prozess in einem anderen Zielstatus.
Betrieb der Prozessengine
Um die Parameter und benötigten Dateipfade oder Volumes darzustellen, haben wir ein Docker-Compose File aus der Camunda Dokumentation abgeleitet, welches außer Zeebe nichts enthält:
services:
zeebe: # https://docs.camunda.io/docs/self-managed/platform-deployment/docker/#zeebe
image: camunda/zeebe:8.4.1
container_name: zeebe
ports:
- "26500:26500"
- "9600:9600"
environment:
- ZEEBE_BROKER_DATA_DISKUSAGECOMMANDWATERMARK=0.998
- ZEEBE_BROKER_DATA_DISKUSAGEREPLICATIONWATERMARK=0.999
- "JAVA_TOOL_OPTIONS=-Xms512m -Xmx512m"
restart: always
healthcheck:
test: [ "CMD-SHELL", "timeout 10s bash -c ':> /dev/tcp/127.0.0.1/9600' || exit 1" ]
interval: 30s
timeout: 5s
retries: 5
start_period: 30s
volumes:
- ./zeebe-data:/usr/local/zeebe/dataFür den Container werden zwei Ports gemappt: 26500 für die gRPC Kommunikation und 9600 für den Startup- und Ready-Check von außerhalb. Ein Volume mappt die Daten aus /usr/local/zeebe/data auf den Host-Ordner zeebe-data, in diesem wird das Eventlog des Brokers gespeichert. An der Speicherkonfiguration -Xmx512m, welche einen maximalen Heap von 512MB definiert, sehen wir, dass die Engine keine großen Speicheranforderungen hat. Für Anwendungsfälle mit höherem Volumen dürften diese jedoch nicht ausreichend sein. Mit einem docker-compose up wird der Broker gestartet.
Projektsetup mit Spring Boot
Wir nutzen Spring Boot für unsere serverseitige Java Applikation, welche mit dem Zeebe Broker interagiert. Als Maven-Dependency fügen wir den Camunda Spring Boot Starter hinzu, welcher die Jobworker für uns konfiguriert und deren Lebenszyklus steuert:
<dependency>
<groupId>io.camunda.spring</groupId>
<artifactId>spring-boot-starter-camunda</artifactId>
<version>8.4.0</version>
</dependency>In der application.properties Datei definieren wir die URL unseres Zeebe Brokers. Da wir in einer Entwicklungs-Umgebung sind, müssen wir mit dem plaintext Property SSL deaktivieren - produktiv würden wir die Einrichtung einer Verbindung über TLS empfehlen:
zeebe.client.broker.gateway-address=localhost:26500
zeebe.client.security.plaintext=trueMit Hilfe der Spring Boot Integration können wir darüber hinaus definieren, welche Prozessinstanzen beim Start unserer Applikation aus dem Klassenpfad heraus deployed werden sollen. Dies erfolgt mit der Annotation @Deployment, welche wir an beliebigen Konfigurationsklassen ergänzen können.
@Configuration
@Deployment(resources = "reminder-process.bpmn")
public class ZeebeConfig {
}In unserem Beispiel geben wir den Dateinamen unserer BPMN-Definition direkt an. Es ist aber auch möglich mit Wildcards zu arbeiten, um etwa sämtliche BPMN Dateien, oder bestimmte Dateien mit einem bestimmten Namensschema zu berücksichtigen.
Start des Reminder-Prozesses
Wir möchten eine neue Prozessinstanz starten, sobald unser Account in einem Posting erwähnt wird. Um mit der Engine zu interagieren, benötigen wir eine Instanz des ZeebeClient, welche wir uns dank der Spring Boot Integration per Dependency Injection übergeben lassen können. Im Beispiel definieren wir den Java Record ProcessInput, welcher die benötigten Eingangsvariablen für den Start einer Prozessinstanz beinhaltet.
@Autowired
private final ZeebeClient zeebeClient;
record ProcessInput(String content,
String statusId,
String visibility,
String account) {};
public Long startReminderProcess(Status status) {
var processInput = new ProcessInput(status.content(),
status.id(),
status.visibility(),
status.account().acct());
var result = zeebeClient
.newCreateInstanceCommand()
.bpmnProcessId("Process_Reminder")
.latestVersion()
.variables(processInput)
.send()
.join();
return result.getProcessInstanceKey();
}Geführt durch einen mehrstufigen Builder erstellen wir nun eine Prozessinstanz, welche aus der Prozessdefinition mit der ID Process_Reminder erstellt wird. Wir möchten diese in der neuesten deployeten Version starten, und die gemappten Inputvariablen übergeben. Der Aufruf von send() sendet den Befehl per gRPC asynchron an die Zeebe Engine; mit join() warten wir auf die erfolgreiche Ausführung, um die ID der neu erstellen Prozessinstanz als Rückgabewert der Methode nutzen zu können.
Ausführen der Programmlogik mit Jobworkern
Damit unser Geschäftsprozess nicht nur ein ansehnliches Bild ist, sondern unsere Applikation orchestriert, müssen wir an Service Tasks einen Typen definieren. Dieser wird von sogenannten Job Workern verwendet, um den Typ der zu verarbeitenden Aufgabe zu identifizieren.
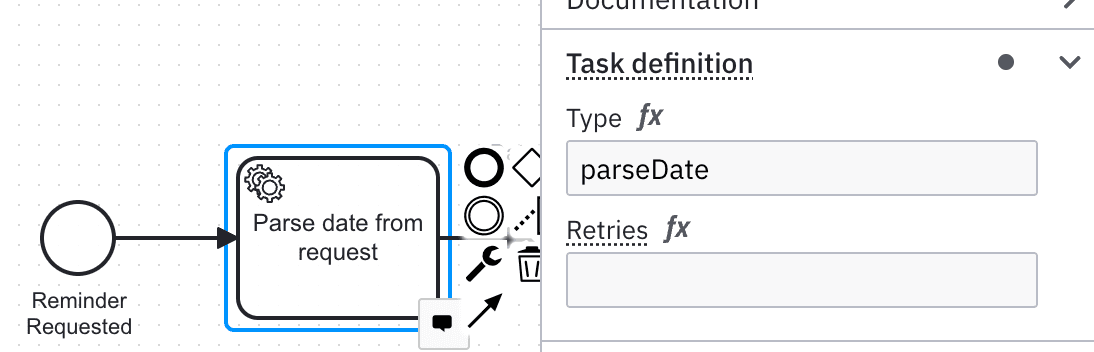
Beim folgenden Beispiel eines Java Jobworkers nutzen wir die Annotation @JobWorker aus dem oben erwähnten Spring Boot Starter um die Verbindung zum Service Task herzustellen. Im Hintergrund pollt unsere Anwendung die Engine per gRPC um zu ermitteln, ob zu verarbeitende Jobs existieren.
public record ParseRequestResponse(boolean dateUnderstood,
ZonedDateTime reminderDate) {};
@JobWorker(type = "parseDate")
public ParseRequestResponse parseRequest(
@Variable String content) {
var matcher = PATTERN.matcher(content);
if(matcher.find()) {
var result = matcher.group(1);
return new ParseRequestResponse(true,
ZonedDateTime.now()
.plusDays(Long.parseLong(result)));
} else {
return new ParseRequestResponse(false, null);
}
}Ist dies der Fall, wird unsere Methode aufgerufen. Der in der Signatur aufgeführte Parameter String content wird hierbei aus den Prozessvariablen abgebildet und an die Methode übergeben. Aus dem content versuchen wir mit Hilfe von regulären Ausdrücken eine Erwähnung der Tage zu extrahieren und addieren diese Tage zum aktuellen Datum um das Datum für den Reminder zu ermitteln. Die Antwort an die Prozessengine geben wir als Rückgabewert der Methode zurück. In unserem Fall haben wir lokal einen Java Record definiert, welcher zwei Variablen enthält: Einen Wahrheitswert, welcher abbildet ob die Anfrage überhaupt verstanden wurde, und ein ZonedDateTime, welches das berechnete Datum der Erinnerung enthält. Die Camunda Spring Integration mappt nach dem Aufruf der Methode jedes Feld des Response Objekts auf eine Prozessvariable und mappt die Feldnamen dabei auf Variablennamen. Wir führen also in diesem Beispiel zwei neue Prozessvariablen ein: dateUnderstood und reminderDate.
Bei der direkten Interaktion mit Posts des sozialen Netzwerks ist das Prinzip sehr ähnlich. Auch hierzu registrieren wir einen JobWorker an der Engine, welche auf den ihm zugeordneten Task lauscht. Wird dieser von der Engine innerhalb einer Prozessinstanz erreicht, wird die mit @JobWorker annotierte Methode aufgerufen, und die Variablen in die Parameter der Methode gemappt.
public record SuccessOutput(String reminderStatusId) {};
@JobWorker(type = "confirmCancellation")
public SuccessOutput confirmCancellation(
@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Na gut, der Timer ist abgebrochen");
var result = mastodonService.replyToStatus(statusId,
message,
visibility);
return new SuccessOutput(result.id());
}Dieser Worker erhält die Information auf welchen Status er antworten soll per statusId, in welcher Sichtbarkeit der Status geschrieben wurde mittels visibility und welchem Account geantwortet wird mit account. Die Status ID benötigen wir, um den Post an den korrekten Vorgänger anzuhängen, den Account um den Nutzer darin zu erwähnen und die Sichtbarkeit des Ausgangsposts, um in der selben Sichtbarkeit zu antworten - wir möchten schließlich nicht öffentlich sichtbar auf eine private Erwähnung antworten. Mit diesen Informationen setzen wir uns die Nachricht aus dem (nicht aufgeführten) Message Template zusammen und senden Sie an einen Server des dezentralen sozialen Netzwerks.
Ähnlich verhält es sich mit den JobWorkern für die anderen Tasks, welche hier nicht mehr im Detail beschrieben werden, aber der Vollständigkeit halber aufgelistet sind.
@JobWorker(type = "confirmReminder")
public SuccessOutput confirmReminder(
@Variable String statusId,
@Variable ZonedDateTime reminderDate,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Hey, alles klar! Ich erinnere dich am %s".formatted(reminderDate));
var result = mastodonService.
replyToStatus(statusId, message, visibility);
return new SuccessOutput(result.id());
}
@JobWorker(type = "respondDateNotUnderstood")
public void replyNotUnderstood(
@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Hi, das habe ich leider nicht verstanden. Schreibe mir 'in x Tagen' oder einfach 'x Tage'");
mastodonService.replyToStatus(statusId, message, visibility);
}
@JobWorker(type = "remindUser")
public void remind(@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account, "Hi, hier ist deine Erinnerung!");
mastodonService.replyToStatus(statusId, message, visibility);
}Einschränkungen
Am Beispiel können wir sehen, dass sich auch mit der "neuen" Camunda Engine kleinere Applikationen umsetzen lassen, ohne einen Kubernetes Cluster für die Infrastruktur zu betreiben. Neben unserer Programmlogik in einer Spring Boot Applikation benötigen wir vorerst nur den Zeebe Broker, welcher dafür auch mehrere Applikationen gleichzeitig bedienen könnte. Ein wichtiges Element von Prozessengines fehlt in unseren Beispiel jedoch: Der Einblick in die laufende Prozessengine. Wie können wir sehen, welche Prozessinstanzen sich in welchem Zustand befinden, oder Incidents betrachten und auflösen? Mit unserem Setup: Gar nicht. Wie eingangs erwähnt, ist es nicht möglich aktuelle Zustände aus dem Zeebe Broker per gRPC abzufragen, wir können nur auf Ereignisse der Engine reagieren. In der vollwertigen Camunda 8 Plattform werden diese Ereignisse mit den Elasticsearch-Exporter in eine Elasticsearch Instanz übermittelt, welche einen abfragbaren Zustand verwaltet. Auf diesem Zustand basieren die Taskliste und die Operate Applikation (vormals: Cockpit), welche nur mit einer kostenpflichtigen Enterprise Lizenz produktiv genutzt werden dürfen. Aus der Community heraus wurde als offene Lösung der Simple Zeebe Monitor entwickelt, welcher die grundlegenden Funktionen für den Einblick und die Interaktion mit Prozessinstanzen bereitstellt. Der Zustand der Prozessinstanzen wird hierfür in Kafka, Hazelcast oder Redis gespeichert und muss ebenfalls mit einem passenden Zeebe Exporter übermittelt werden. Hierzu benötigen wir also erneut zusätzliche Infrastruktur.
Fazit
Auch für kleinere Softwareprojekte kann die neue Prozessengine hinter Camunda 8, Zeebe, interessant sein. Keinesfalls müssen wir die Komplexität des vollen Camunda 8 Deployments bedienen. Ebenso ist es für die Nutzung von Zeebe nicht erforderlich, die Camunda Cloud oder eine Camunda 8 Enterprise Lizenz zu erwerben. Sind wir bereit etwas zusätzliche Infrastruktur zu pflegen, können wir mit dem Simple Zeebe Monitor sogar eine Überwachung und Administration der Prozessinstanzen ermöglichen. Während dies für kleine Projekte, Hobby- oder Open Source Applikationen ein gangbarer Weg sein kann, kommt dies eher nicht für die Migration von Camunda 7 Applikationen infrage, welche in der Community Edition produktiv in Unternehmen im Einsatz sind oder User Tasks nutzen.
Über den Autor
