Lightweight Processes with Camunda and Zeebe
With the transition from Camunda 7 to 8, the process engine transforms from a library that can be integrated into applications to a comprehensive platform with many components. While exploring the recommended setup, we encounter Helm charts and deployments with eight or more components, some of which are only available for enterprise customers in production. This article demonstrates how lightweight process applications can be created using the open-source core component Zeebe.
Table of Contents
A New Architecture
It's rare for a new major version of software to bring about such a significant paradigm shift: while the Camunda Platform in version 7 was fully integrable into Java applications, Camunda 8 is now based on Zeebe, an independent component with which our code communicates via gRPC. Instead of representing the state of business processes in a database, the operations of the processes are stored in an event log. The goal of the Camunda developers was to create a process engine that is infinitely scalable horizontally. As a result, Camunda 8 can process a significantly higher throughput than Camunda 7, which could only handle as many requests as its central, relational database.
A frequently discussed point about the new platform is that the complexity of an average Camunda installation is higher than it was for the old engine. A productive deployment for Camunda 7 included the engine itself, a relational database, optionally a task list for processing user tasks, and a cockpit for inspecting running processes. Except for the database, we could bundle all these components in a single Java application, which we could deploy using familiar methods.
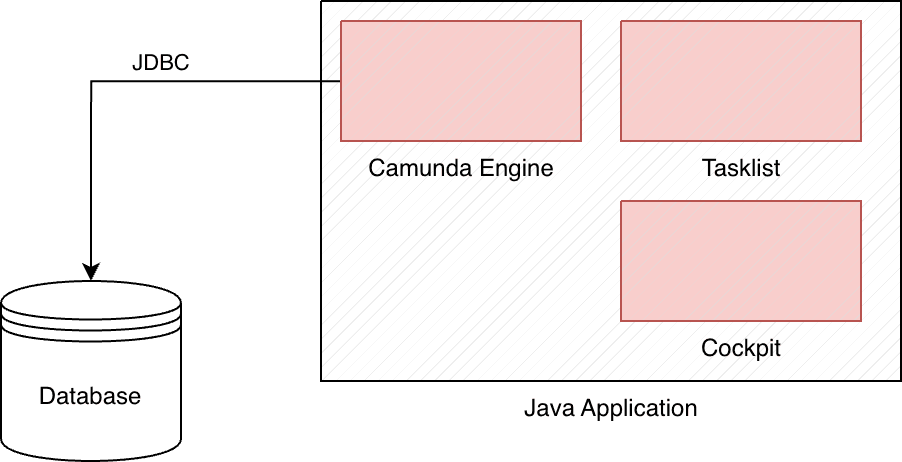
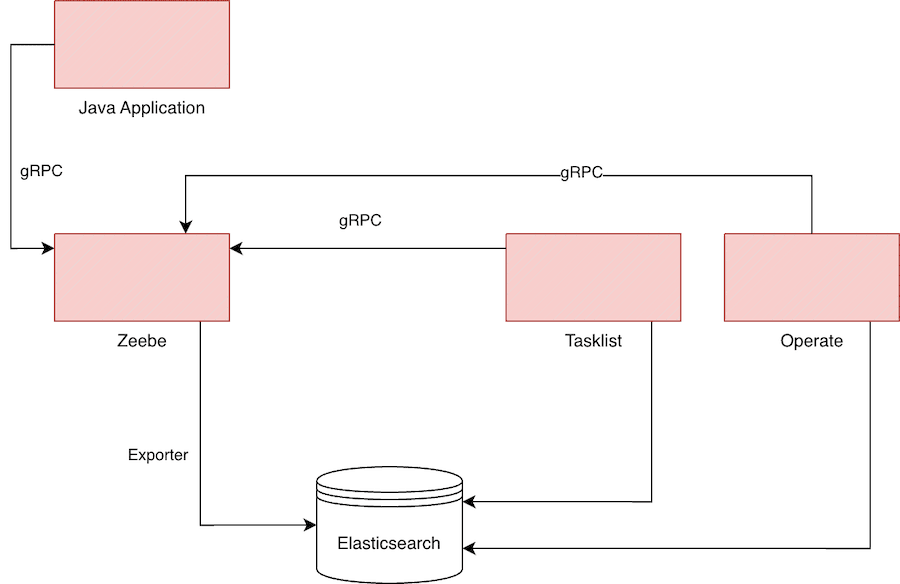
The changes made with the Camunda 7 Community Edition have caused uncertainty among its users. Not everyone has technical requirements for a process engine that justify managing so many components and maintaining a Kubernetes cluster. The alternative use of the in-house SaaS product, Camunda Cloud, might make sense for smaller companies, but here the costs scale with the executed process instances, so a use case should be carefully calculated. The break-even point, at which self-hosting becomes worthwhile, is likely only surpassed with a considerable number of process instances per hour.
But what about smaller projects that could benefit from process orchestration and the use of BPMN, but would no longer be profitable with the use of the SaaS offering or the operation of more complex infrastructure? In the following example, we will explore this question by building and operating a lightweight process.
Example: A Reminder Bot for Social Networks
A "Reminder-Bot" is a great example of a lightweight process. It involves an account that is mentioned in a message with the addition "in x days," and after this period, responds with a post as a reminder. As a BPMN process, this could look something like this:
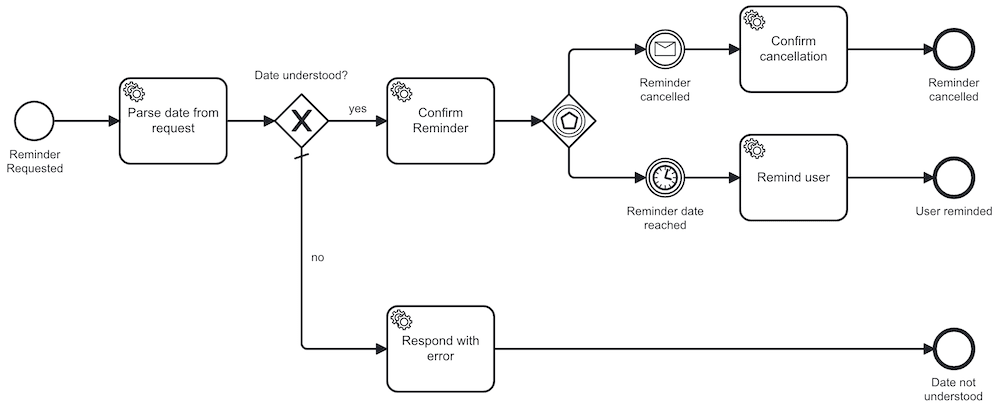
Operation of the Process Engine
services:
zeebe: # https://docs.camunda.io/docs/self-managed/platform-deployment/docker/#zeebe
image: camunda/zeebe:8.4.1
container_name: zeebe
ports:
- "26500:26500"
- "9600:9600"
environment:
- ZEEBE_BROKER_DATA_DISKUSAGECOMMANDWATERMARK=0.998
- ZEEBE_BROKER_DATA_DISKUSAGEREPLICATIONWATERMARK=0.999
- "JAVA_TOOL_OPTIONS=-Xms512m -Xmx512m"
restart: always
healthcheck:
test: [ "CMD-SHELL", "timeout 10s bash -c ':> /dev/tcp/127.0.0.1/9600' || exit 1" ]
interval: 30s
timeout: 5s
retries: 5
start_period: 30s
volumes:
- ./zeebe-data:/usr/local/zeebe/dataFor the container, two ports are mapped: 26500 for gRPC communication and 9600 for the startup and ready check from outside. A volume maps the data from /usr/local/zeebe/data to the host folder zeebe-data, where the broker's event log is stored. From the memory configuration -Xmx512m, which defines a maximum heap of 512MB, we can see that the engine does not have high memory requirements. However, for use cases with higher volume, this might not be sufficient. The broker is started with a docker-compose up command.
Project Setup with Spring Boot
We use Spring Boot for our server-side Java application, which interacts with the Zeebe broker. As a Maven dependency, we add the Camunda Spring Boot Starter, which configures the job workers for us and controls their lifecycle:
<dependency>
<groupId>io.camunda.spring</groupId>
<artifactId>spring-boot-starter-camunda</artifactId>
<version>8.4.0</version>
</dependency>zeebe.client.broker.gateway-address=localhost:26500
zeebe.client.security.plaintext=trueWith the help of this Spring Boot integration, we can also define which process instances should be deployed from the classpath when our application starts. This is done using the @Deployment annotation, which we can add to any configuration classes.
@Configuration
@Deployment(resources = "reminder-process.bpmn")
public class ZeebeConfig {
}@Autowired
private final ZeebeClient zeebeClient;
record ProcessInput(String content,
String statusId,
String visibility,
String account) {};
public Long startReminderProcess(Status status) {
var processInput = new ProcessInput(status.content(),
status.id(),
status.visibility(),
status.account().acct());
var result = zeebeClient
.newCreateInstanceCommand()
.bpmnProcessId("Process_Reminder")
.latestVersion()
.variables(processInput)
.send()
.join();
return result.getProcessInstanceKey();
}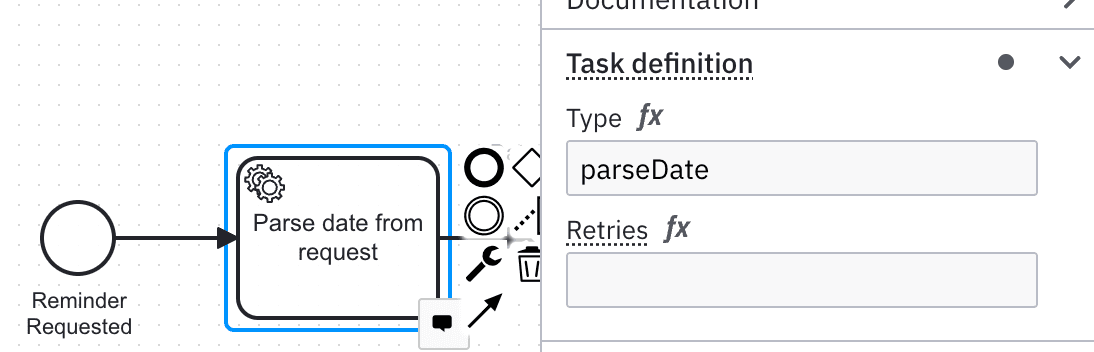
public record ParseRequestResponse(boolean dateUnderstood,
ZonedDateTime reminderDate) {};
@JobWorker(type = "parseDate")
public ParseRequestResponse parseRequest(
@Variable String content) {
var matcher = PATTERN.matcher(content);
if(matcher.find()) {
var result = matcher.group(1);
return new ParseRequestResponse(true,
ZonedDateTime.now()
.plusDays(Long.parseLong(result)));
} else {
return new ParseRequestResponse(false, null);
}
}public record SuccessOutput(String reminderStatusId) {};
@JobWorker(type = "confirmCancellation")
public SuccessOutput confirmCancellation(
@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Na gut, der Timer ist abgebrochen");
var result = mastodonService.replyToStatus(statusId,
message,
visibility);
return new SuccessOutput(result.id());
}@JobWorker(type = "confirmReminder")
public SuccessOutput confirmReminder(
@Variable String statusId,
@Variable ZonedDateTime reminderDate,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Hey, alles klar! Ich erinnere dich am %s".formatted(reminderDate));
var result = mastodonService.
replyToStatus(statusId, message, visibility);
return new SuccessOutput(result.id());
}
@JobWorker(type = "respondDateNotUnderstood")
public void replyNotUnderstood(
@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account,
"Hi, das habe ich leider nicht verstanden. Schreibe mir 'in x Tagen' oder einfach 'x Tage'");
mastodonService.replyToStatus(statusId, message, visibility);
}
@JobWorker(type = "remindUser")
public void remind(@Variable String statusId,
@Variable String visibility,
@Variable String account) {
var message = MESSAGE_TEMPLATE.formatted(account, "Hi, hier ist deine Erinnerung!");
mastodonService.replyToStatus(statusId, message, visibility);
}About the author
